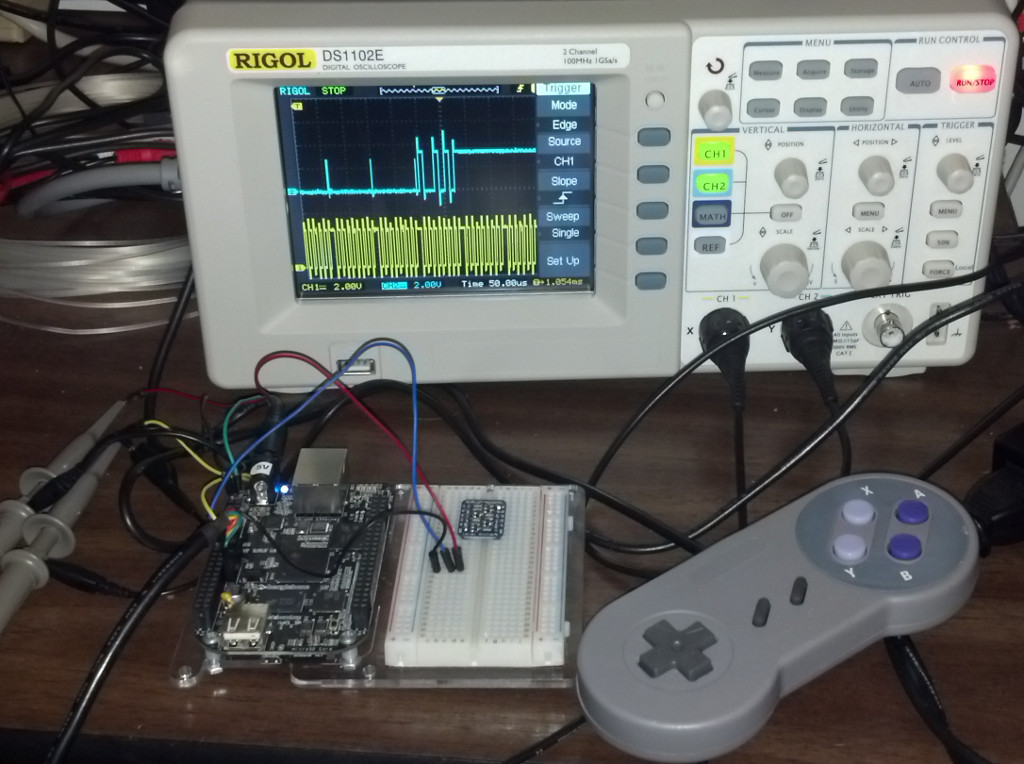
I have been working on accessing the #beagleboneblack #SPI from userspace by memory-mapping the SPI registers, and I wanted to make a post about it to see if anyone else has been working on something similar so that we can compare notes. This work comes from my observation that, when using the spidev driver, the ioctl() call to TX/RX a SPI message (SPI_IOC_MESSAGE()) takes far longer than the actual time spent performing the TX/RX. I have always mmap()'d the GPIO registers to interact with the GPIO pins, so why not do the same thing with the SPI registers?
I’m still using the spidev driver, but not for the actual transmission. I set up the device tree overlay to mux for SPI0, and I open and configure the SPI0 channel via ioctl() calls to “/dev/spidev1.0”. I also mmap() the SPI registers (MCSPI_CH0CONF/STAT/CTRL, MCSPI_TX0/RX0, etc.) by opening “/dev/mem” and mapping a single 4K page at the base address of 0x48030000. For each message transmission, I set up MCSPI_CH0CONF for the various transmission settings and to lower the CS signal, poll the CHSTAT RX and TX status bits in MCSPI_CH0STAT, and write/read the MCSPI_TX0/RX0 registers to handle the data transmission. After the transmission is done, the CS signal is raised again via MCSPI_CH0CONF.
Overall, it works well. I am able to quickly change transmission modes (POL/PHA), speeds (48MHz clock divider), word size, etc. without the ioctl() calls, and I can gate GPIO pins with the CS to talk to multiple SPI slave devices. Since I can control the speed and configuration on-the-fly quickly for each message, I can talk to many different slave devices at different speeds on different messages without the overhead of the ioctl() calls to change the channel settings.
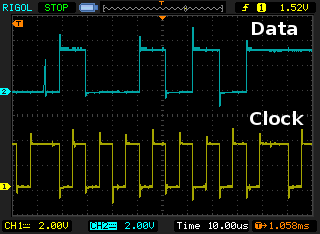
Looking at my scope’s output, I can see that the signal looks good (even at the full 48MHz clock speed). I’ve found that if you slam the MCSPI_CH0STAT by polling it over and over, you will receive a bus error. But, if you poll only 500 or 1000 times before timing out, it works out better. Also, you can probably busy-wait a bit more between checks. You’ll want to usleep() immediately prior to sending your message(s) to ensure that you’re sending your SPI data from userspace at the start of your current timeslice. You could use sched_setscheduler() to boost the priority of your SPI comm thread to real-time priority, but I didn’t see the benefit in this. If you need real-time guarantees, you can always use the PRU to talk to the SPI registers.
The spidev driver will outperform the userspace approach for larger transmissions. In my measurements, the break-even point for an 8-bit word message sent at 12MHz is about 250 bytes. At 50 bytes, it takes 90us in userspace and 140us in the kernel (36% faster). At 100 bytes, this becomes 167us/231us (28% faster). At 160 bytes, DMA turns on inside the kernel driver and the time becomes 262us/321us (18% faster). At 300 bytes, the timing is 475us/456us (4% slower). But, userspace will still allow you to implement multiple chip select lines via GPIOs and quickly change transmission parameters between messages.